Artificial Intelligence (AI) techniques are quickly becoming central to businesses’ digital transformation by augmenting, and in many cases supplanting, traditional data analytics techniques. These techniques bring proactive and prescriptive capabilities to a company’s data-driven decision-making process, giving companies that adopt them early a distinct competitive advantage. Those that adopt them late will be left behind.
Intel recognizes that AI methods, most notably machine learning and deep learning, are now critical components of company workloads. To address the need to both train and, arguably more importantly, have AI models make decisions faster, Intel has put these workloads front and center with the new 2nd Generation Intel® Xeon® Scalable processor line.
2nd Generation Intel® Xeon® Scalable Processors
2nd Generation Intel® Xeon® Scalable processors bring a host of new and improved capabilities, including the ability to deploy Intel® Optane™ DC Persistent Memory, improved DRAM speeds, greater processing capability for traditional instruction sets such as single precision FP32, and new processing capability for deep learning workloads with the new Intel® Deep Learning Boost instruction set.
Deep Learning Boost on 2nd Generation Intel® Xeon® Scalable Processors
Deep learning is the process of developing models using artificial neural networks, which consist of many independent processing units, or neurons, connected in a dense graph. Neural networks have demonstrated astonishing ability to identify unknown or unforeseen patterns in all sorts of data and have been applied to domains ranging from image and video recognition and analysis, to audio and language transformation, to time-series data and anomaly detection analysis.
The process of using neural networks for developing cutting-edge models is broken into two phases: training, where existing data is used to teach the neural network how to identify patterns; and inference, where the trained model is exposed to new data and expected to make appropriate decisions. And while the process of training neural networks has been the focus of hardware and software innovation for several years, it is in the inference where businesses are receiving benefit from their AI efforts.
Inference has different hardware requirements than training. Training requires half-precision or single-precision floating point arithmetic and the ability to process many large vectors of similar data simultaneously. Inference has much lower total compute requirements, is focused more heavily on latency (time-to-decision), and can take advantage of lower-precision numerical formats such as 8-bit and 16-bit integers.
The 2nd Generation Intel® Xeon® Scalable processor line focuses primarily on this second (inference) phase with an entirely new capability known as Deep Learning Boost. Intel® Deep Learning Boost brings reduced precision arithmetic (8-bit and 16-bin integers) to Xeon’s 512-bit wide vector units (AVX512). This is a huge capability for reduced precision inference because Deep Learning Boost-enabled Intel® Xeon® processors can simultaneously process 64 8-bit integers (or 32 16-bit integers) in a single hardware instruction! Couple this with the ability to perform fused operations, such as Fused Multiply Add (FMA) on these wide low-precision vectors, and the throughput of the system goes up substantially.
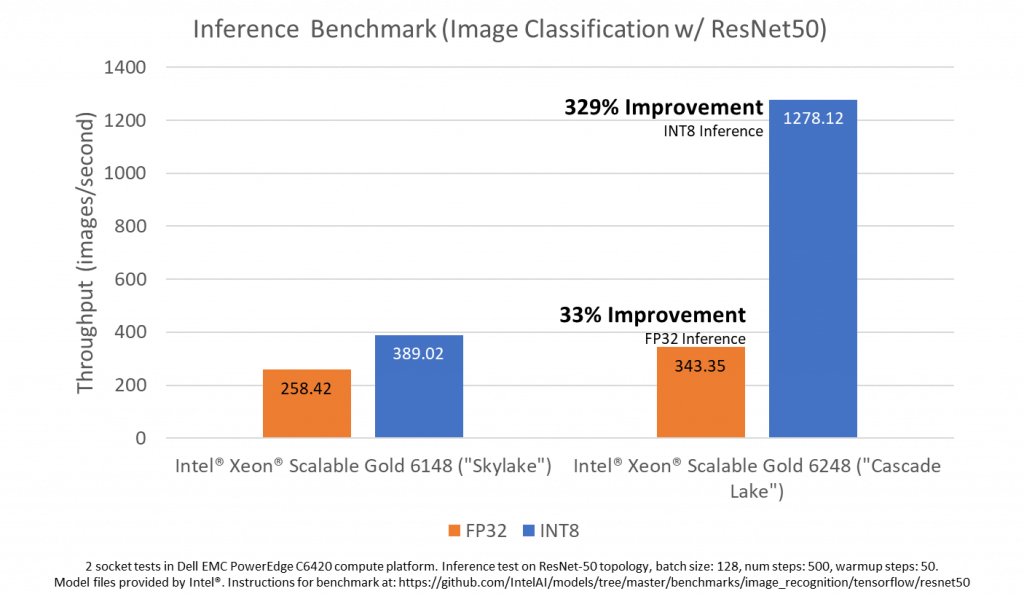
Dell EMC has been benchmarking the realizable performance improvements that Intel® Deep Learning Boost can bring the neural network inference. The figure above shows how much improvement your organization could realize by deploying 2nd Generation Intel® Xeon® Scalable processors with Intel® Deep Learning Boost. While 1st Generation Intel® Xeon® Scalable processors (codenamed “Skylake”) are capable of processing 258 images per second on the ResNet-50 inference benchmark in single-precision (FP32), and 389 image per second in reduced 8-bit integer precision, the new instructions that Deep Learning Boost brings to 2nd Generation Intel® Xeon® Scalable processors can more than triple the throughput in 8-bit integer precision to 1278 images per second!
Why This Matters
What does this mean for your business? Each inference your AI model makes is an insight you didn’t have before, or a workload you’ve automated that removes a barrier to a decision. Each of those insights, each of those removed barriers can translate to a new sale, an additional upsell, or a faster investment decision. That is money in your company’s pockets.
As companies undergo digital transformation, making use of AI – and deep learning specifically – will be critical to keeping your company competitive in a data-driven world. And while training AI models has been the talk of this early stage, the inference is going to be the way in which your business realizes the benefits of AI. Dell EMC PowerEdge servers powered by 2nd Generation Intel® Xeon® Scalable processors with Intel® Deep Learning Boost can help your business realize the full potential of AI through higher performance model inference. And higher performance translates to better business.
