Artificial Intelligence (AI), Machine Learning (ML), and Deep Learning (DL) are more than just flare for an expo booth. Companies are transforming their business practices, driving productivity, and creating new opportunities with the power of data and AI. Faced with limited resources, organizations must decide whether to scale their AI processes up or out. This key decision will better leverage the talent of an organization’s data scientists, capturing operational efficiencies, transforming decision making, and delivering stronger business results.
So, what are AI, ML, and DL, and how are they related? DL is a subset of ML, and ML is subset of AI – clear as mud right? AI can independently sense, reason, act, and adapt. ML and DL use mathematical algorithms to ‘learn’ as opposed to being explicitly told what to do as in expert systems (imperative programming using a lot of ‘if, then else’). ML techniques use a variety of algorithms to create mathematical models which can then be used to predict an output based on some new input. DL structures algorithms in layers to create an artificial “neural network” which can learn and improve with vast amounts of data to make a better output (a decision) based on some new input.
Some characteristics of ML and DL are shown below in Figures 1 and 2:

Figure 1
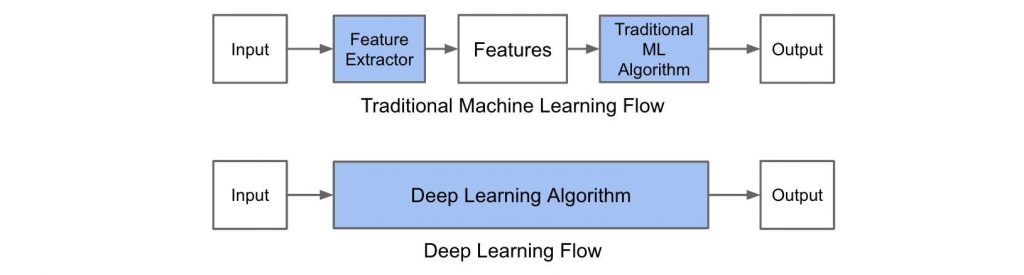
Figure 2
As an example of ML and DL, think of the problem of predicting someone’s weight (Figure 3). It could be a simple data set with height and weight then, using ML, you come up with line of best fit. Conversely, you could have tons of image data labeled with weight, then DL could refine the model with many more considerations, such as facial features, therefore improving accuracy.

Figure 3
The fuel of AI is lots of data; advanced models, algorithms and software; and high-performance infrastructure. As a general rule, if you are fortunate and have all three fuels, your organization should use DL. If you have two out of three, one, or none, use ML.
The AI journey is a challenge. When we talk to our customers, they cite limited expertise, inadequate data management, and constrained budgets. Their business challenge is threefold: Define, Develop, and Deploy. They must define the use cases, requirements, business goals for artificial intelligence. Then, they must develop the data sources, infrastructure, trained models, and refinement process surrounding an AI system. Finally, they need to deploy the AI-enabled systems with tracking tools and inferencing, at scale.
Now that we have covered the seemingly daunting challenges of implementing AI, let’s dive into the upbeat topic of a scale up or scale out strategy for AI. Scaling up implies adding more resources to an existing system. In the case of AI, that means how many domain specific architecture elements (DSA) are in an individual server. DSA is becoming the code name to mean anything that accelerates beyond general purpose computing, such as GPUs, ASICs, FPGA, IPUs, etc. Scaling out, however, means adding more systems, each with some number of GPUs. Think of this in server terms as a 32-socket server vs 2-socket server. This is like the 30+ year old argument of mainframe vs x86 scale out. Scale out economics emerged the clear victor.
For example, consider a family with independent transportation needs. The family could buy a Hennessy Venom GT – the fastest car on the planet – and one by one they could share it to rapidly meet their transportation needs. Or, they could buy n number of sufficient-performance cars and meet all their needs all the time.

Figure 4
Just as the family will simultaneously need to take concurrent trips, corporations on the AI journey will need more than one data scientist. Our job in technology is to make all data scientists productive all the time.
The first set of data below uses MLperf (MLperf builds fair and useful benchmarks for measuring training and inference performance of ML hardware, software, and services) across the Dell portfolio of domain specific architecture-enabled (DSA) servers. In Figure 5, you can see the scaling from 2 V100 GPUs in the Precision 5820 to 4 V100 in a PowerEdge C4140 to 8 V100 in the DSS 8440 to 8 in an NVLink-enabled server. The 8-NVLink server performs slightly better than the 8-PCIe-enabled DSS8440 (note the DSS8440 can support ten V100’s).
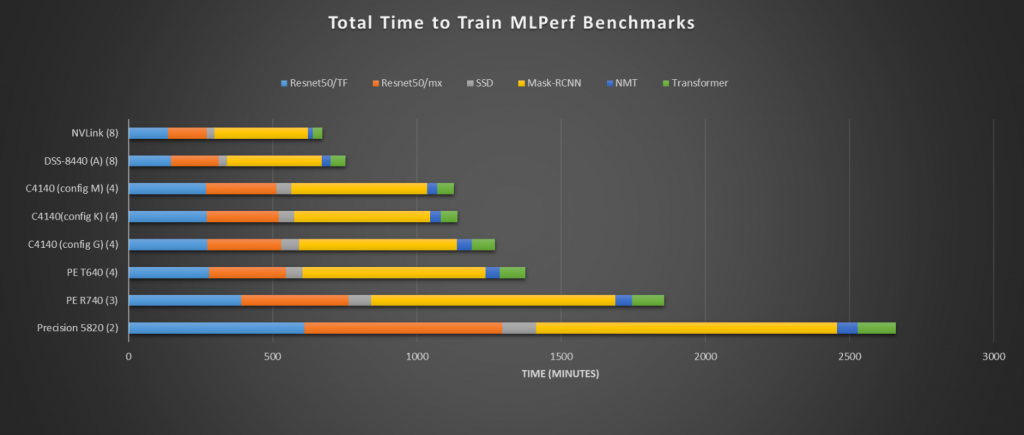
Figure 5
If you look closer at the individual 8-GPU scores below in following two figures, the scores are very close with exception of translation and recommendation for the two different 8-GPU cases. That said, the performance gap has closed between NVLink vs PCIe with proper PCIe topologies and better PCIe switch peer-to-peer support, and it will close more with PCI data speeds of Gen4 and Gen5 which is 16GT/s and 32GT/s respectively vs Gen3 which was 8GT/s.
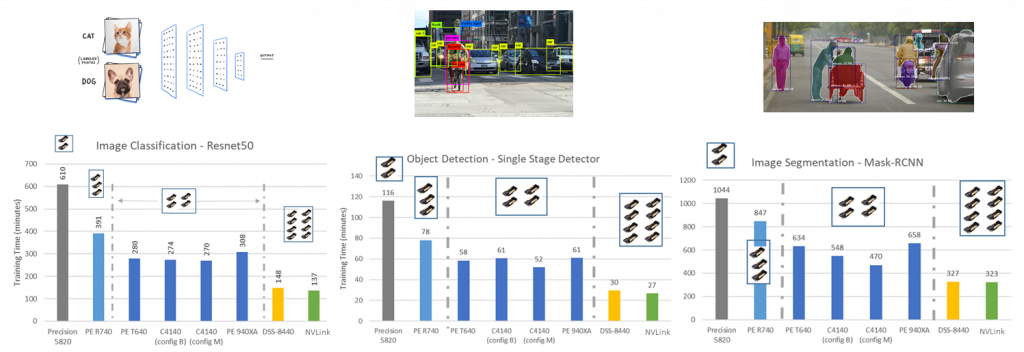
Figure 6
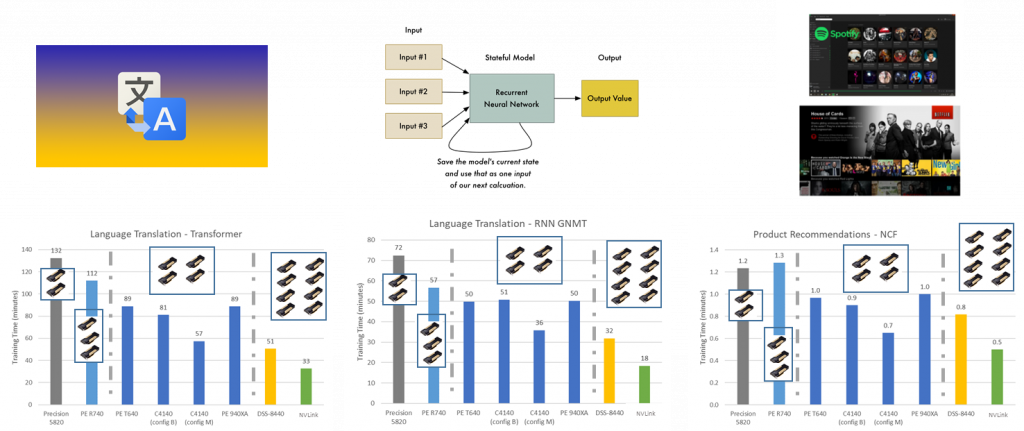
Figure 7
If we take the same MLPerf, compare an 8-NVLink server to 2x 4-node NVLink servers, and spread the sub benchmarks across the two servers, we can now get all the work done faster than a single 8-NVLink server (Figure 8).

Figure 8
This checks out because, according to Amdahl’s law, the speed-up is not linear in large scale parallelism. Thus, it is important to pick a point on the speed-up scale before it gets into the non-linear region and to stay in the scale out economic sweet spot. Figure 9 shows scaling for 1-to-4 and 1-to-8 GPUs, as you can see, 1-to-4 GPU scaling has higher efficiency across the board (Figure 9).
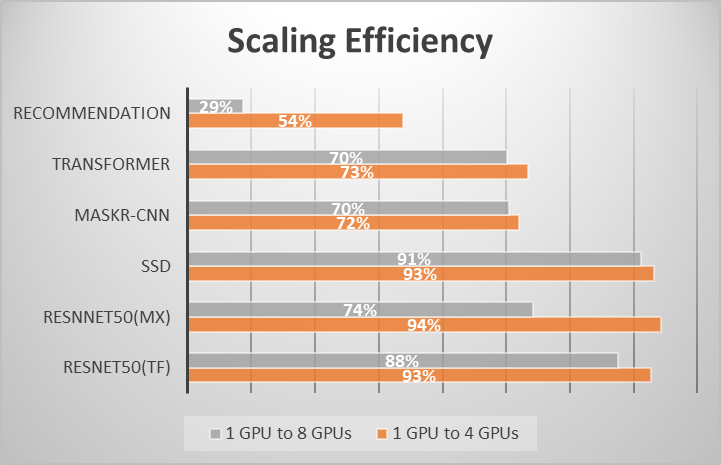
Figure 9
Mark Twain popularized the saying, “There are lies, dammed lies, and statistics.” If he were still a journalist in the Bay Area today, he would turn our attention toward the pitfalls of benchmarks. Benchmarks in the right context are fine, but reduced to simple metrics, benchmarks can cause serious problems. Leaders must understand the underlying drivers of benchmarks to make informed decisions. Continuing our scale out or in example, 2x scale out nodes outperform a single scale up node using MLperf, the best industry benchmark. The scale out C4140 is also the best MLperf-per-dollar option for AI, which reflects the optimization point of using economic scale out nodes. Additionally, if you noticed in the news, VMware recently announced the acquisition of Bitfusion, which is a scale out approach to elastic AI infrastructure.
Now, this is not to say 8 GPU+ systems don’t have their place, just like we still have 8 to 32-socket x86 servers, they have their place and need. But there is an economic law and Amdahl law at play which suggest that the economics of scale out win except in the corner cases. Scaling GPUs is impacted by two main variables: data size and optimized code. If the data set is too small and scaling inefficiently with more GPUs, you end up shuffling parameters between GPUs more than doing computation on the data. Most models and use cases in practice for DL in enterprise will be best run on one GPU because of dataset sizes and quality of code. AI-proficient companies have hired skilled “ninja” programmers due to use cases/datasets that require training across 8+ GPUs to meet time-to-solution requirements. Everybody else, good luck with getting better performance on two or more GPUs than a single GPU.
The fact is this, companies on an AI journey will have tens or hundreds of data scientists, not just one. It is our job in technology to make sure all data scientists are as productive as possible. If one data scientist finishes her job fast while the others are drinking coffee and waiting for their turn, the company is not productive. Much like buying a super car to share with your spouse, only one person can be happy at a time. As monk and poet John Lydgate wisely wrote, “You can please some of the people all of the time, you can please all of the people some of the time, but you can’t please all of the people all of the time.” Well, in this case you can make all the data scientist happy all the time by enabling productivity to all, all the time – by investing in scale out and proper GPU workload orchestration.
I want to thank Ramesh Radhakrishnan, Distinguished Engineer, Office of Server & Infrastructure Systems CTO, Dell EMC – for the great work in these benchmarks.
If you have questions, want to go deeper, or want to understand the Dell EMC family of DSA enabled servers, please contact one of our friendly Dell EMC sales representatives. For more musings on this and other topics, please follow me on LinkedIn.
To read more about performance testing across Dell PowerEdge servers related to Machine learning and Deep learning, please visit hpcatdell.com.
To learn more about PowerEdge servers, including the C4140 and DSS 8440, visit dellemc.com/servers, or join the conversation on Twitter @DellEMCservers.