As the year comes to a close, VCE is helping customers plan their technology investment for 2015. This year, two topics stand out – big data and analytics and third platform applications – which are becoming key investment areas for accelerating growth and innovation in 2015 and beyond. We’ll take a deeper dive into these topics this week in a two part series, starting with big data and analytics and Enterprise Hadoop.
 2014 saw a significant uptick in customer requests to extend the VCE experience for big data workloads, especially Hadoop. They’re ready to move Hadoop deployments from experimentation and R&D efforts to production.
2014 saw a significant uptick in customer requests to extend the VCE experience for big data workloads, especially Hadoop. They’re ready to move Hadoop deployments from experimentation and R&D efforts to production.
Hadoop scales up from a single server to thousands of machines, allowing customers to utilize large sets of data at a lower cost. These big data sets provide key insights for enterprises to gain a competitive edge through sales and marketing analytics, sentiment analysis, risk and fraud analytics, machine learning, data mining, the Internet of Things (IoT), and much more.
But harnessing the benefits of this new technology can be a challenge for even the most sophisticated enterprises. Commodity, disparate systems do not scale for large deployments, they cause:
- Compliance and governance concerns
- Risks of losing unprotected data
- Delayed response times across multiple systems in the analytic value chain
- Maintenance overhead of managing failed components
- Challenges in availability and business continuity
- Difficulties in predicting power and footprint expansions
Managing structured and unstructured data to accelerate time to insight demands an integrated approach to deploying Hadoop in the context of their existing analytic investments.
VCE provides a modern infrastructure for Hadoop, ensuring availability, reliability and simplicity to optimize value, especially when moving applications from development and quality assurance to production and preparing for expansion. Hadoop deployments enable multi-tenant, virtualized analytic services to support multiple business units, and they must maintain service level agreements (SLAs) for those projects, making expansion capabilities across the analytic eco-system even more important. The Vblock Systems and VCE technology extension for EMC Isilon storage allows customers to select the storage, compute and network that suit their SLAs, workload characteristics and budgets, and are easy to upgrade and expand with enterprise IT visibility and control.
A leading telecom service provider tapped the VCE solution to run their analytic workloads, including Hadoop and Splunk, in conjunction with their other enterprise analytic and custom solutions. Their data sets were used for customer churn analytics, fraud prevention, outage assessments and new offer developments aligned with SLAs.
A minute of downtime for the large telecom service provider could cause immeasurable disruption to the company, consumers, other enterprises or countries. It could expose the telecom company to fraud, revenue losses, large overhead costs and reputational risk. Therefore, it was imperative for the service provider to minimize risks and ensure the same quality of service by choosing VCE to drive their analytics strategy.
Since the service provider was already utilizing Vblock Systems and EMC Isilon for other workloads, the VCE technology extension for EMC Isilon provided easy expansion of storage capabilities – allowing them to reuse data and applications for multiple initiatives that involve analytics, image storage, back-up and archiving.
Enterprises traditionally used a commodity direct attached storage (DAS) model for Hadoop deployments. So while the benefits, such as better security, governance and availability, on shared infrastructure model were appealing, some organizations were concerned that separating compute and storage as independently scaling resources may incur unfavorable latencies in performance.
In order to examine how the shared infrastructure benefits organizations, VCE sponsored ESG validation of Vblock Systems and VCE™ technology extension for EMC® Isilon® storage to deploy enterprise Hadoop.[footnote]ESG Lab Review, VCE Vblock Systems with EMC Isilon for Enterprise Hadoop, November 2014[/footnote] The compute and storage layers with network scaling of Vblock Systems with VCE technology extensions for EMC Isilon to run Hadoop can be extended via HDFS, NFS, SMB and other protocols as shown below.
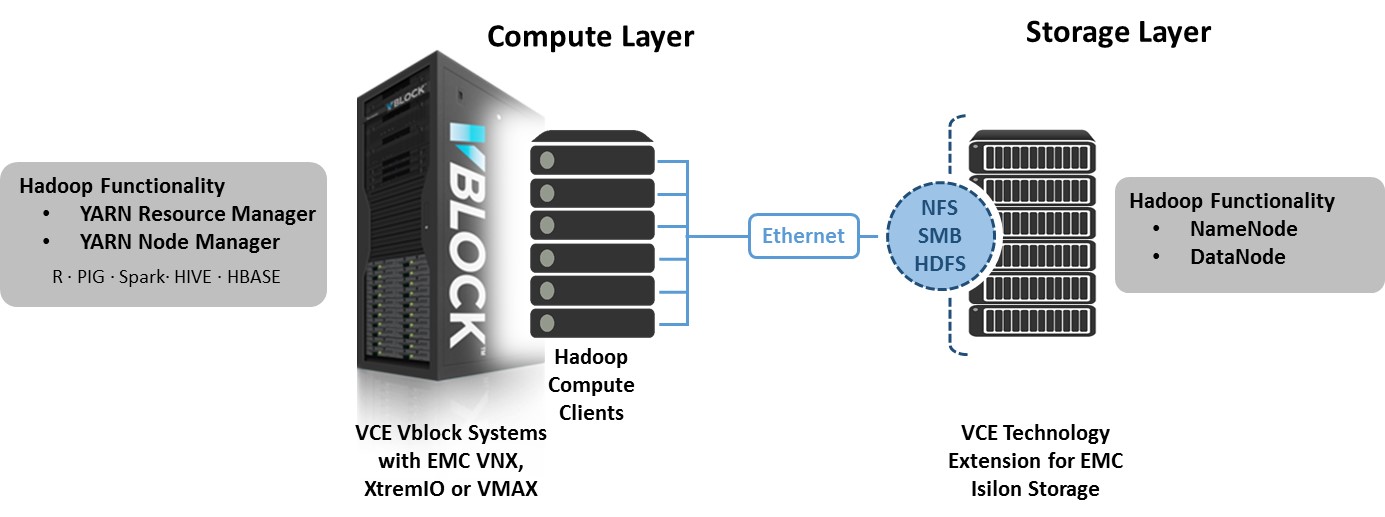
In addition to discussing security, governance, availability and scalability, the ESG Lab Report analyzes how our shared infrastructure approach works in terms of performance for virtual environments. As shown below, Vblock Systems and VCE™ technology extension for EMC® Isilon® storage outperformed Traditional Hadoop based on DAS in TeraGen, TeraSort and TeraValidate testing.

“By leveraging an industry-proven Integrated computing platform (ICP) in VCE Vblock Systems and combining it with EMC Isilon and VMware vSphere Big Data Extensions, organizations get a fully integrated platform that meets and grows with their big data and analytics requirements.
— Tony Palmer, Senior Lab Analyst, ESG
Click the links to read the full ESG Lab Review on VCE Vblock Systems with EMC Isilon for Enterprise Hadoop and the Enterprise Hadoop blog post by Mike Leone, ESG Lab Engineer.
If you are progressing to enterprise Hadoop as part of your 2015 initiative in big data and analytics, it is an opportune time for you to rethink the investment given the technological maturity and innovations of the modern infrastructure.
Later this week, I will discuss the role of integrated systems for accelerating time to value from the third platform applications.
Add to the conversation – What are your 2015 plans for big data and analytics? How do you plan to evolve your data centers to accommodate the increasing data-driven approach to manage business in the next several years? Are you interested in modernizing your infrastructure to speed time to insight end-to-end by managing structured and unstructured data alike?